今天我們要討論的是overfit和underfit。可以透過下表看的出來overfit的話,是模型學到太好太fit training data。在看training data的結果時,您可能會誤判認為他train的很好。其原因為generation不好。當testing data預測的時候,會使的預測結果非常差。面對Underfit的問題時,主要就是Model針對training data就學不起來,導致不管在training set或者testing set都得到不佳的效果。而最好的結果就是圖中間的Good Fit,針對Training set或者Testing set都有很好的結果。但這兩種問題都與模型容量和訓練資料的多寡有關。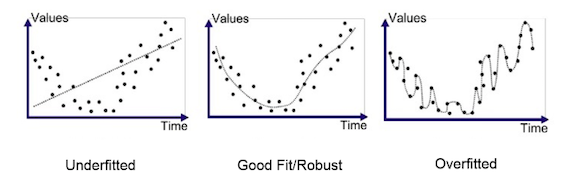
在機器學習的領域中,會說容量 是模型擬合數的能力。通常,越是複雜的模型其容量越高,但是容易造成Overfit。反之,越是簡單的模型其容量越低,卻容易導致underfit。
假設是個線性回歸的模型他的函數是y=wx+b,如果他的資料分布為非線性分布,則線性回歸的模型就比較難fit這次資料的規律,因此這模型的容量較低,相較如果今天是個9次方的模型他就比較有能力可以fit非線性資料分布,顧他的容量就比較大。
為了降低模型複雜度,Regularization會在loss function上加入懲罰項(Penalty),來限制模型中的權重,降低權重或者變為0。
Dropout的意思是捨棄模型參數,捨棄的比例可以自行決定,簡單來說就是在每次訓練都使用不同的神經元學習,可以有效避免神經網路過於依賴局部特徵,造成網路的稀疏性。

